Martyn Hill, while testing his brand new Tetroid SuperGoldCard clone, has discovered a strange bug where his QL crashed when he was loading a _scr file into the QL’s screen memory. It works fine without the SuperGoldCard. A lot of theories were put forward, like:
- It’s a problem with the SuperGoldCard: turns out it works fine when QDOS or a very early Minerva version is used instead
- It’s connected to the memory timing of the screen area: turns out is also happens in fast memory
- It’s connected to the 68020 processor: turns out is also happens on the 68000 processor
- The SuperGoldCard patches are wrong: I’ve analyzed all the patches and they all look fine. In fact the patch code is identical to Minerva’s code except for the timing loops. Still, it appeared to work with earlier versions of the patches, which makes it weird again.
Personally I couldn’t care less if Microdrives work or not and the fact that this bug was not discovered for so long strongly implies that most other people also don’t use Microdrives with SGC systems anymore. Still I have trouble resisting a good puzzle so I had a look. And then another one. And then ten more because this was a very elusive bug.
The problem is that not only is the bug located in ROM locations that are hard to debug anyway, the MDV code is so time critical that it’s impossible to step through the code. So how can one debug this? Hardware to the rescue! The SuperGoldCard very conveniently has a parallel port on board that can be accessed very simply by the software. By connecting a logic analyzer to all 8 data lines and sprinkling output commandos throughout the MDV code I can get a live trace of what the code is doing or output the contents of registers byte-by-byte.

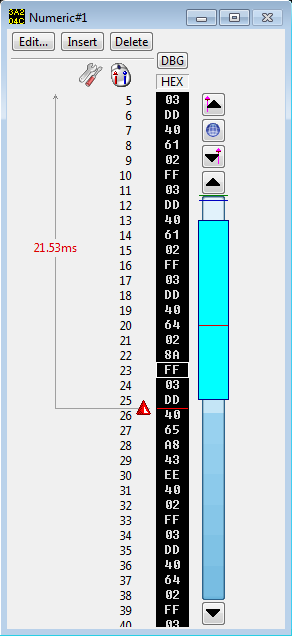
Bytes output by the instrumented driver
In hindsight I should have found the problem much earlier because of the symptoms, but that’s easy to say after you know what’s going wrong. Let’s make a little quiz, here’s the code part with the problem and you can try to spot the bug:
move.w #blksize,d0 full block normally (512)
cmp.b lstblok(a0),d7 is it the last file block?
bne.s not_last no - copy to end of it
move.w lstbyte(a0),d0 get the number of bytes in last block
not_last
lsl.w #blkbits-1,d7
add.l d7,d7 is it the first file block?
lea -md_deend(a1,d7.l),a5 where to put data normally
bne.s not_frst
moveq #md_deend,d1 yes - move on past the file header
add.l d1,a4
add.l d1,a5
sub.w d1,d0 copy fewer bytes
not_frst
ror.l #2,d0 long words, and save odd byte count
bcc.s unbf_dbr carry means there is an odd word to do
move.w (a4)+,(a5)+ if so, do it
bra.s unbf_dbr
unbf_lop
move.l (a4)+,(a5)+ move a long word
unbf_dbr
dbra d0,unbf_lop
add.l d0,d0 see if there's an odd byte to go
bpl.s notabyte
move.b (a4)+,(a5)+ if so, do it
notabyteKeep in mind that the code is not generally broken, it sometimes works! The problem also appears for the first block, so you can pretty much ignore the special handling of the last block. Found it? I’ll wait…
.
.
.
.
.
The “ror.l #2,d0” is a pretty clever way to both divide the register by 4 (because the copy loop does long words) while still remembering the odd bytes that also need to be copied. But it relies on one thing: that bits 16 and 17 of the register are zero. These bits are shifted into the lower 16-bits and are then used by the dbra instruction, which means that if they are set instead of copying 128 long words it will copy at least 16384. Talk about a buffer overflow!
You should now also see why it sometimes works. Remember earlier that I wrote “In fact the [MDV] patch code is identical to Minerva’s code except for the timing loops.”. The timing code in the original Minerva ROM is hidden behind a macro but in the end looks like this:
; For delays 5 to 19µs
moveq #([us]*15-38)/4,d0 four byte sequence
ror.l d0,d0
; For delays 21 to 309µs
moveq #([us]*15-50)/36,d0 six byte sequence
dbra d0,*
; ... etc, other variants are similarFor the (S)GC this is exchanged by loops like this:
move.w gmt_fgap,d0 ; 2800 us
dbra d0,*I guess everybody can see the difference now, the original code clears the upper word of D0 and the replacement code does not. And as it happens the upper word is $FFFF from an earlier call to md_slave. All in all a very subtle difference, hard to spot by just looking at the code.
The solution I chose is it to exchange the “move.w #blksize,d0” line with “move.l”. That adds two bytes (every byte is precious in Minerva, there are not many left!), but this is the minimum I can get away with without relying on side effects of outside code, which is how this bug was introduced in the first place.
As this is the second fix from me for Minerva 1.98 I will have to think about how to mark these modified Minerva versions as increasing the version number is a no-go unfortunately. 1.99 is the last number we can use in theory before running into extended compatibility problems and I’m not even sure about this, 1.98 is still a safer choice.
Anyway, I hope this was interesting to read, leave a comment if you want. I will soon release a fixed binary version.
Oh my goodness!
I’m afraid that I couldn’t spot the issue and had to read-on 🙁
I recall scanning that part of the code, but it was too dense for me (or, I was!)
Thanks again Marcel!
You sir, are a flipping genius.
Cheers,
Norm.
Thanks, Norm! Now tell that to my wife 😀
Better not…. 😉
I’ve just suggested to Marcel that replacing the “move.w #blksize,d0” with “moveq #blksize/2,d0; add.w d0,d0” would be a better accommodation, but I’m a bit rusty, and that doesn’t help at all. Unfortunately “blksize” is 512, so I hope “moveq #blksize/4,d0; lsl.w #2,d0′ might be better. I don’t have my trusty 68008 manual to hand. Maybe I’m being silly? (Two glasses of Merlot)
True royalty in my blog, I’m honored 🙂 And one can see how you managed to squeeze Minerva into 48kb as well! Actually blksize/4 sign extends negatively, but I will gladly use blksize/8 and save the two additional bytes again, thanks!
I said I was a bit rusty!
I do slightly wonder though – why I ever did that “move.w #blksize,d0”. It’s not as if it really mattered – the miniscule cycle saving (if that is true, even). I just did a search through all the sources to see where I have any other “move.w #”, just in case any are as poor choices as this one. Difficult to tell – there are a lot of hits, most of which are obviously fine.
N.B. As an aside, I think I’m right to say that a “move.w” into an address register always sign extends to long, and never affects the status register bits.
P.S. Also note that I did not squeeze Minerva into 48K. I squeezed it into 330 bytes less than that. There was some piece of hardware that used mapped addresses up at something like $BEC0. I think I only had ten bytes free. Maybe there were a few more .
Also, the Mk2 uses the four byte addresses at $BFDC to waggle output I2C lines and read its data in..
Oh, ok! Do you remember what kind of hardware this was? I do know about Mk2, but what other hardware reserves space in the lower 48k? $BEC0 would mean one cannot change anything at all anymore. My German version already breaks this barrier easily, but then I have done this mostly for myself and fellow QL-SD users, where it doesn’t matter. One feature I thought about adding was support for hex literals in Basic, I’m badly missing those compared to SMSQ/E. But not sure how much that would add.
Pingback: Marcel Kilgus Site Updates | QUANTA